
Artificial General Intelligence (AGI) is the ultimate goal of many AI researchers and enthusiasts. It refers to the ability of a machine to perform any intellectual task that a human can do, such as reasoning, learning, creativity, and generalization. However, we are still far from achieving AGI with our current AI systems. One of the most advanced AI systems today is GPT-4, a large multimodal model created by OpenAI that can take text and pictures as input and outputs text. So how far away from AGI is GPT-4 and what do we need to do to get there?
What GPT-4 is capable of?
GPT-4 is a successor of GPT-3.5, which was already impressive in its ability to generate coherent and fluent text on various topics and domains. GPT-4 improves on GPT-3.5 by being more reliable, creative, and able to handle much more nuanced instructions than its predecessor. For example, it can pass a simulated bar exam with a score around the top 10% of test takers; in contrast, GPT-3.5’s score was around the bottom 10%. It also generates medium-sized working programs and can reason to a certain extent. The context window of GPT-4 is 32K tokens which allows it to produce entire programs.
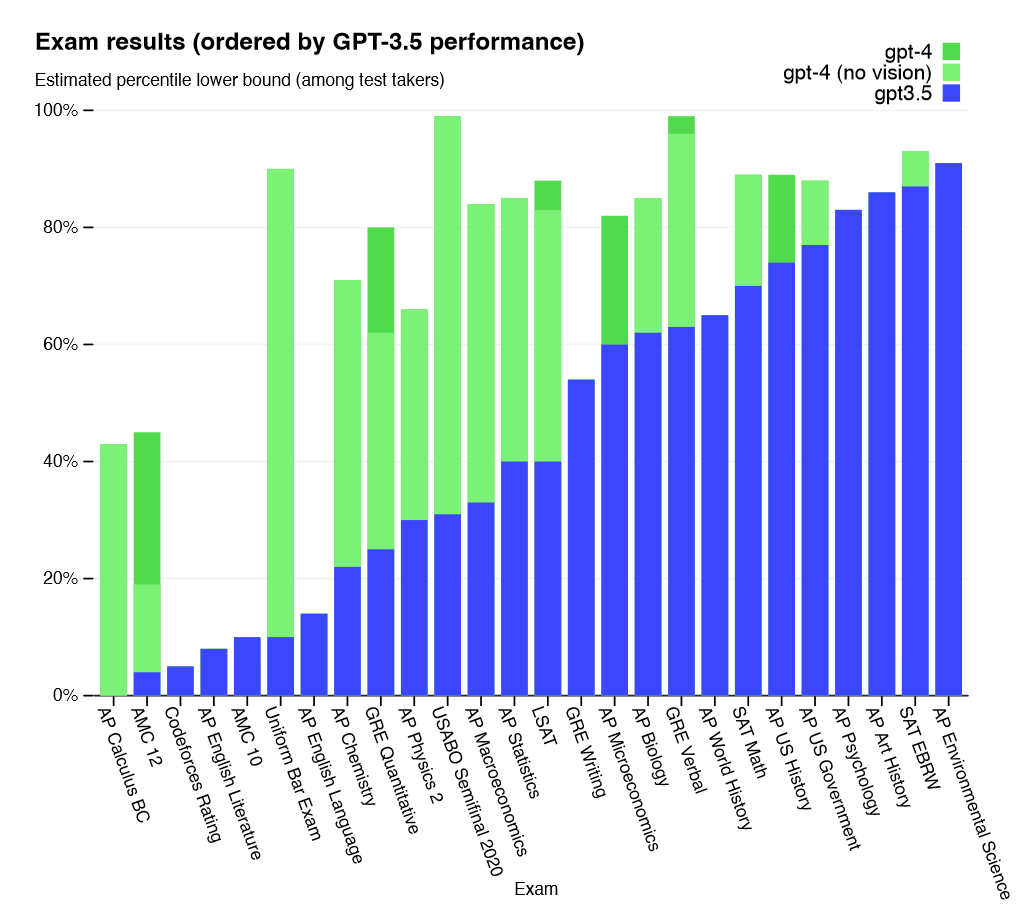
GPT-4 also adds a new feature: visual input. It can accept image and text inputs together and emit text outputs that are relevant to both modalities. For instance, it can describe what is happening in an image or understand its relevance in a given context. This makes GPT-4 more versatile and useful for various applications that require multimodal understanding.
However, despite its impressive capabilities, GPT-4 is still far from being able to perform all the tasks that humans can do with language and images. It still lacks some crucial components that are necessary for achieving AGI.
What do we need to add?
One of the main limitations of GPT-4 is that it has no memory. It cannot remember what it has said, outside of its context window, or learned before, and cannot use it for future reference or inference. This means that it cannot build long-term knowledge or relationships with its users or other agents. It also means that it cannot handle complex reasoning tasks that require multiple steps or facts that exceed its context window.
Another limitation of GPT-4 is that it has no access to tools that can help it solve problems or learn new skills. For example, it cannot use the Internet to search for information on the web; Wolfram Alpha to compute mathematical expressions; databases to store and retrieve data; or other APIs to interact with external services. This limits its ability to acquire new knowledge or perform tasks beyond outputting text.
A third limitation of GPT-4 is that it has no inner thinking. It is strictly an input-output machine that produces exactly one piece of text for every input it gets. In between inputs it does nothing and is in the same state every time. The ability to simulate possible situations is called mental simulation and is one of the key abilities of the human brain. It is a fundamental form of computation in the brain, underlying many cognitive skills such as mindreading, perception, memory, and language. The fact that all Transformer based AI systems are not capable of that in their current form, is, in my opinion, the main reason why AGI is still not in sight.
How do we do this?
To overcome these limitations and move closer towards AGI, we need to add some features and functionalities to GPT-4 that can substitute for these shortcomings.
One possible way to do this is by using chain prompts. Chain prompts are sequences of inputs and outputs that guide the model through a series of steps or actions towards a desired goal. For example, we can use chain prompts to instruct GPT-4 to search for information on the Internet. By using chain prompts, we can extend GPT-4‘s capabilities and make it more powerful and transparent. Instead of giving the Model the input directly, we would ask it which parts of the input it needs more information on, and then we get a list of keywords selected by the model that we feed into a search engine. In the last step, we add the information that we got to the original input and give the user the final output.
Another possible way to do this is by using Toolformer. Toolformer was proposed by Meta that allows us to integrate external tools into LLMs by using special tokens that represent tool names. The model would be fine-tuned on text examples of API calls. For example, we can use Toolformer to write:
Input: What is 2 + 2?
Output:The answer is <calculator args=”2+2″>4</calculator>.
This way, GPT-4 can learn to use tools by observing how they are used in natural language contexts. Toolformer can also handle complex tool compositions and nested tool calls. Some tools that would drastically enhance the capabilities of GPT are
Wolfram Alpha (Math)
A calendar (temporal awareness),
A search engine (information gathering)
A database(memory)
A command line (general control)
Especially the last part is really special. By giving a powerful enough model access to a computer, and combining this with other methods such as chain prompting, we could enable unlimited possibilities.
One special case of these techniques that I want to highlight is code execution. An LLM that can run generated code itself and receive the output could build the programs to solve every task it gets. This starts with writing simple functions to solve equations to controlling a smart home or fine-tuning itself.
We can also add memory this way by giving it access to a database. We could use chain prompting to ask the model if parts of the input or output should be saved for the future and combine it with a writing call to the database. We then could use embeddings to search the database for every input and extract relevant information. Embeddings are vector representations of text that decode the meaning of the text. Asking the model about an appointment with your doctor would be represented by a vector that is similar to the vector that represents the information about the appointment in the database. The solution is not perfect but would add memory to the model.

Where we are right now
We already see the start of these augmentations. The first one was BingGPT which augments GPT-4 with a search engine. The most recent and impressive one is Microsoft’s copilot for Microsoft 365, which combines GPT-4 with all the Office tools and their Microsoft Graph system, which also gives it access to all your documents. Other companies will follow even though the integration is limited since the model is not Open source and OpenAI are the only ones able to fine-tune it. But for most of these techniques, you can use Langchain which is a new code library that contains many of the described ways to improve GPT.4
What we could see until the end of the year
All these methods are not mutually exclusive and can be combined in different ways depending on the task and context. Many companies are already or going to integrate GPT-4 into their products. And the more tools can be controlled by natural language the easier it will be for other LLMs to use them. Until the end of the year, we will see Language Models talking to each other. I can see a near future where we have our own custom model that talks to BingGPT, Copilot, or other software and takes on the role of a dirigent of other instances of GPT-4. But there are also risks. Giving the model too much control could lead to chains of mistakes if the model is not powerful enough and makes mistakes or it could lead to a complete takeover and fast takeoff if future models like GPT-5 or 6 are too powerful. This is unlikely as long as OpenAI holds tight control over the development and execution of these models, but the competition is growing and broadly available Hardware and software are becoming better and better. This year will be the rise of AI and next year could be the birth year of proto-AGI.
Update: shortly after I finished this post, this paper was released. It talks about a form of memorizing transformer, which I found to be quite relevant to this post.
German version below
Von GPT-4 zu Proto-AGI
Artificial General Intelligence (AGI) ist das ultimative Ziel vieler AI-Forscher und Enthusiasten. Es bezieht sich auf die Fähigkeit einer Maschine, jede geistige Aufgabe auszuführen, die ein Mensch tun kann, wie etwa das Denken, Lernen, Kreativität und Generalisierung. Allerdings sind wir noch weit davon entfernt, AGI mit unseren derzeitigen AI-Systemen zu erreichen. Eines der fortschrittlichsten AI-Systeme aktuell ist GPT-4, ein großes multimodales Modell, dass von OpenAI erstellt wurde und Text und Bilder als Eingabe nimmt und Text als Ausgabe produziert. Also wie weit ist GPT-4 von AGI entfernt und was müssen wir tun, um dorthin zu gelangen?
Was kann GPT-4?
GPT-4 ist der Nachfolger von GPT-3.5, dass bereits beeindruckend ist in seiner Fähigkeit, zusammenhängenden und flüssigen Text zu verschiedenen Themen und Domänen zu generieren. GPT-4 verbessert GPT-3.5, indem es zuverlässiger, kreativer und in der Lage ist, viel nuanciertere Anweisungen als sein Vorgänger zu handhaben. Zum Beispiel kann es eine simulierte Bar-Prüfung mit einer Punktzahl um die Top 10% der Testteilnehmer bestehen; im Gegensatz dazu lag die Punktzahl von GPT-3.5 bei rund 10% am unteren Ende. Es generiert auch mittelgroße funktionierende Programme und kann bis zu einem gewissen Grad schlussfolgern. Das Kontextfenster von GPT-4 umfasst 32 tausend Token, was es ermöglicht, ganze Programme zu erstellen.
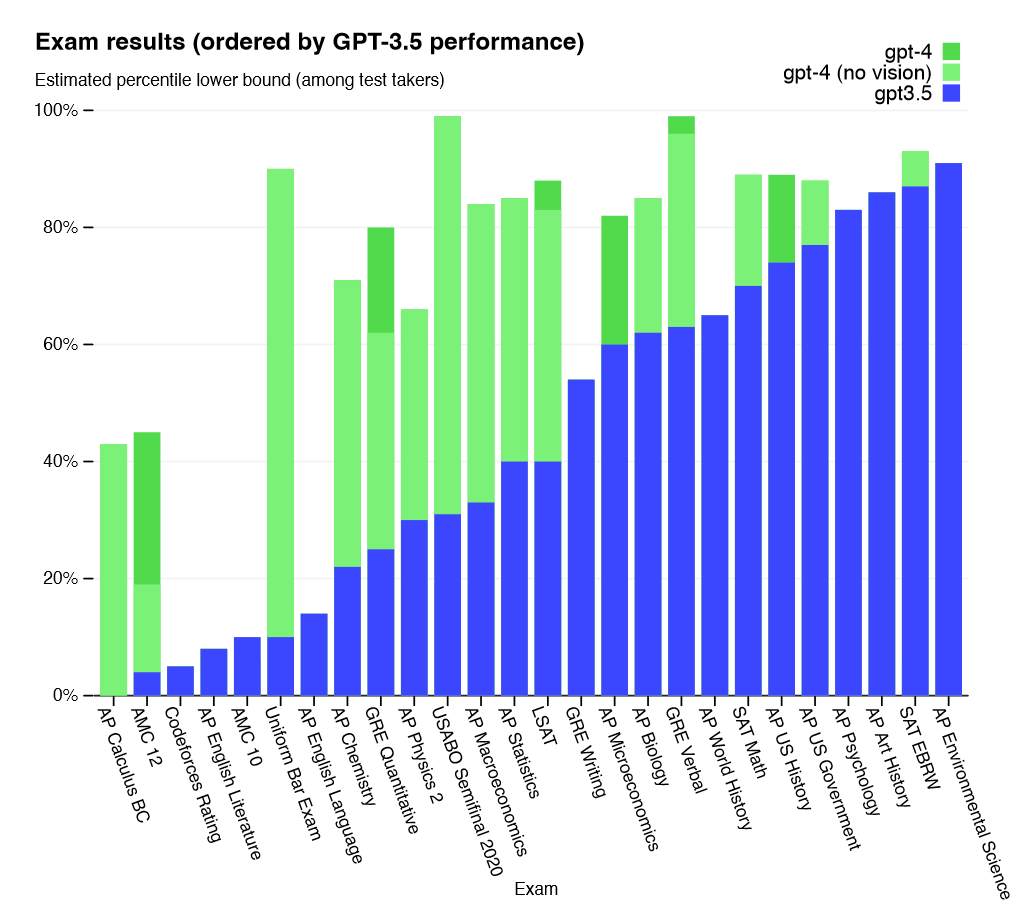
GPT-4 fügt auch eine neue Funktion hinzu: visuelle Eingabe. Es kann sowohl Bild- als auch Texteingaben akzeptieren und Textausgaben liefern, die für beide Modalitäten relevant sind. Zum Beispiel kann es beschreiben, was in einem Bild passiert, oder den inhalt eines Bildes in einen Kontext einzuordnen. Dies macht GPT-4 vielseitiger und nützlicher für verschiedene Anwendungen, die ein multimodales Verständnis erfordern.
Was noch fehlt?
Trotz seiner beeindruckenden Fähigkeiten ist GPT-4 jedoch noch weit davon entfernt, alle Aufgaben ausführen zu können, die Menschen mit Sprache und Bildern bewältigen können. Es fehlen noch einige wesentliche Komponenten, die für die Erreichung von AGI notwendig sind.
Eine der Hauptbeschränkungen von GPT-4 ist, dass es kein Gedächtnis hat. Es kann sich nicht daran erinnern, was es gesagt hat, außerhalb seines Kontextfensters oder was es zuvor gelernt hat, und kann es nicht für zukünftige Referenzen oder Rückschlüsse verwenden. Dies bedeutet, dass es kein langfristiges Wissen oder Beziehungen zu seinen Benutzern oder anderen Agenten aufbauen kann. Es bedeutet auch, dass es keine komplexen Denkaufgaben bewältigen kann, die mehrere Schritte erfordern oder Fakten überschreiten, die sein Kontextfenster übersteigen. Eine weitere Einschränkung von GPT-4 ist, dass es keinen Zugang zu Tools hat, die ihm helfen können, Probleme zu lösen oder neue Fähigkeiten zu erlernen. Es kann z.B. nicht das Internet nutzen, um nach Informationen im Web zu suchen; Wolfram Alpha zur Berechnung mathematischer Ausdrücke; Datenbanken zur Speicherung und Abfrage von Daten oder andere APIs zur Interaktion mit externen Diensten. Dies begrenzt seine Fähigkeit, neues Wissen zu erwerben oder Aufgaben jenseits des Textausgabe zu erledigen. Eine dritte Einschränkung von GPT-4 ist, dass es kein inneres Denken hat. Es ist streng genommen eine Input-Output-Maschine, die für jede Eingabe genau ein Textstück produziert. Zwischen den Eingaben tut es nichts und ist jedes Mal im gleichen Zustand. Die Fähigkeit, mögliche Situationen zu simulieren, wird als mentale Simulation bezeichnet und ist eine der Schlüsselkompetenzen des menschlichen Gehirns. Sie ist eine grundlegende Form der Berechnung im Gehirn und liegt vielen kognitiven Fähigkeiten wie Gedankenlesen, Wahrnehmung, Gedächtnis und Sprache zugrunde. Die Tatsache, dass alle auf der Transformer-Technologie basierenden KI-Systeme in ihrer derzeitigen Form dazu nicht in der Lage sind, ist meiner Meinung nach der Hauptgrund, warum AGI noch nicht in Sicht ist.
Wie können wir das erreichen?
Um diese Einschränkungen zu überwinden und uns der AGI näher zu bringen, müssen wir GPT-4 einige Funktionen und Eigenschaften hinzufügen, die diese Mängel ausgleichen können. Eine mögliche Methode dafür sind sogenannte “Chain Prompts“. Chain Prompts sind Folgen von Eingaben und Ausgaben, die das Modell durch eine Reihe von Schritten oder Aktionen hin zu einem gewünschten Ziel führen. Zum Beispiel können wir Chain Prompts verwenden, um GPT-4 anzuweisen, im Internet nach Informationen zu suchen. Mit Chain Prompts können wir die Fähigkeiten von GPT-4 erweitern und es leistungsfähiger und transparenter machen. Anstatt dem Modell die Eingabe direkt zu geben, würden wir es fragen, welche Teile der Eingabe mehr Informationen benötigen, dann bekommen wir eine Liste von Schlüsselwörtern, die vom Modell ausgewählt wurden und die wir in eine Suchmaschine eingeben. Im letzten Schritt fügen wir die erhaltenen Informationen der ursprünglichen Eingabe hinzu und geben dem Benutzer die endgültige Ausgabe.
Eine weitere mögliche Methode hierfür ist die Verwendung von Toolformer. Toolformer wurde von Meta entwickelt und ermöglicht uns, externe Tools in LLMs zu integrieren, indem wir spezielle Tokens verwenden, die Toolnamen darstellen. Das Modell würde mit Textbeispielen von API-Aufrufen verfeinert werden. Zum Beispiel können wir Toolformer verwenden, um Folgendes zu schreiben:
Eingabe: What is 2 + 2?
Ausgabe: The answer is <calculator args=”2+2″>4</calculator>.
Auf diese Weise kann GPT-4 lernen, Tools zu verwenden, indem es beobachtet, wie sie in natürlichen Sprachkontexten verwendet werden. Toolformer kann auch komplexe Toolzusammensetzungen und verschachtelte Toolaufrufe verarbeiten. Einige Tools, die die Fähigkeiten von GPT drastisch verbessern würden, sind
Wolfram Alpha (Mathematik)
Kalender (zeitliche Kenntnisse)
Suchmaschine (Informationsbeschaffung)
Datenbank (Speicher)
Commandozeile (generelle Kontrolle).
Besonders der letzte Punkt ist sehr wichtig. Indem wir einem ausreichend mächtigen Modell Zugang zu einem Computer geben und dies mit anderen Methoden wie Chain Prompting kombinieren, könnten wir unbegrenzte Möglichkeiten eröffnen. Ein spezieller Fall dieser Techniken, den ich hervorheben möchte, ist die Ausführung von Code. Ein Sprachmodel, das generierten Code selbst ausführen und die Ausgabe empfangen kann, könnte Programme zum Lösen jeder Aufgabe erstellen. Dies beginnt mit dem Schreiben einfacher Funktionen zur Lösung von Gleichungen bis hin zur Steuerung eines Smart Homes oder der eigenen Verbesserung.
Auf diese Weise können wir dem Modell auch Zugriff auf eine Datenbank geben, um so den Speicher zu erweitern. Wir könnten Chain Prompting nutzen, um das Modell zu fragen, ob Teile der Eingabe oder Ausgabe für die Zukunft gespeichert werden sollen, und es mit einem Schreibbefehl an die Datenbank kombinieren. Anschließend könnten wir Embeddings verwenden, um die Datenbank nach jeder Eingabe zu durchsuchen und relevante Informationen zu extrahieren. Embeddings sind Vektor-Textdarstellungen, die die Bedeutung des Textes entschlüsseln. Wenn wir das Modell beispielsweise nach einem Termin mit unserem Arzt fragen, wird ein Vektor erstellt, der ähnlich dem Vektor ist, mit dem die Informationen über den Termin in der Datenbank dargestellt werden. Die Lösung ist zwar nicht perfekt, würde aber dem Modell Gedächtnis hinzufügen.
Der aktuelle Stand
Wir sehen bereits den Beginn dieser Erweiterungen. Die erste war BingGPT, die GPT-4 mit einer Suchmaschine erweitert. Die neueste und beeindruckendste ist Microsofts Copilot für Microsoft 365, eine Kombination aus GPT-4 und allen Office-Tools sowie ihrem Microsoft Graph-System, das auch Zugriff auf alle deine Dokumente gibt. Andere Unternehmen werden folgen, obwohl die Integration begrenzt ist, da das Modell nicht Open Source ist und nur OpenAI es feinabstimmen kann. Besonders hervorheben möchte ich Langchain eine code bibliothek die viele der hier beschrieben Techniken seh vereinfacht
Was noch diesen Jahr passieren kann
All diese Methoden schließen einander nicht aus und können je nach Aufgabe und Kontext auf unterschiedliche Weise kombiniert werden. Viele Unternehmen integrieren bereits oder werden GPT-4 in ihre Produkte integrieren. Und je mehr Werkzeuge von natürlicher Sprache gesteuert werden können, desto einfacher wird es für andere LLMs sein, sie zu nutzen. Bis Ende des Jahres werden wir sehen, wie Sprachmodelle miteinander sprechen. Ich kann mir eine nahe Zukunft vorstellen, in der wir unser eigenes benutzerdefiniertes Modell haben, das mit BingGPT, Copilot oder anderen Software spricht und die Rolle eines Dirigenten für andere Instanzen von GPT-4 übernimmt. Aber es gibt auch Risiken. Wenn das Modell zu viel Kontrolle erhält und nicht leistungsstark genug ist wird es Fehler machem, welche zu Ketten von Fehlern führen können, oder anders herum könnte es zu einem vollständigen Kontrollverlust der Menschen und einer explosionsartigen Entwickung von künstlicher Intelligenz kommen, wenn zukünftige Modelle wie GPT-5 oder 6 zu leistungsfähig sind. Dies ist unwahrscheinlich, solange OpenAI eine strenge Kontrolle über die Entwicklung und Ausführung dieser Modelle ausübt, aber der Wettbewerb wächst und die allgemein verfügbare Hardware und Software werden immer besser. Dieses Jahr wird das Aufkommen von KI sein und nächstes Jahr könnte das Geburtsjahr von Proto-AGI sein.
Da ich nach einer deutschen Version der Posts gefragt wurde ist dies mein erster Versuch Posts zweisprachig zu machen. Ich freue mich über Feedback und kann auf Wunsch auch gerne noch einzelne ältere Posts übersetzen. (Die Übersetzung ist von GPT-3.5 und enhält sprachliche Fehler und suboptimale Formulierungen.)
Update: kurz nachdem ich diesen Aritkel fertig hatte, wurde dieses Paper veröffentlicht. Es geht um eine Form von Transformer mit Gedächnis, was sehr relevant für diesen Artikel ist.
Leave a Reply