
Large Language Models (LLMs) are machine learning-based tools that are able to predict the next word in a given sequence of words. In this post, I want to clarify what they can and cannot do, how they work, what their limitations will be in the future, and how they came to be.
History
With the recent surge in public awareness surrounding Large Language Models (LLMs), a discourse has arisen concerning the potential benefits and risks associated with this technology. Yet, for those well-versed in the field of machine learning, this development represents the next step in a long-standing evolutionary process that began over half a century ago. The first language models were developed over 50 years ago and used statistical approaches that were barely able to form correct sentences.
With the rise of deep learning architectures like recurrent neural networks (RNN) and Long-Short-Term Memory (LSTM) neural networks, they became more powerful but also started to grow in size and needed data.
The emergence of GPUs, and later on specialized processing chips called TPUs, facilitated the construction of larger models, with companies such as IBM and Google spearheading the creation of translation and other language-related applications.
The biggest breakthrough was in 2017 when the paper “Attention is all you need” by Google introduced the Transformer. The Transformer model used self-attention to find connections between words independent of their position in the input and was, therefore, able to learn more complex dependencies. It was also more efficient to train which meant it could train on larger data sets. OpenAI used the Transformer to build GPT-2, the most powerful language model at its time, which developed some surprising capabilities which led to the idea that scaling these models up would unlock even more impressive capabilities. Consequently, many research teams applied the Transformer to diverse problems, training numerous models of increasing size, such as BERT, XLNet, ERNIE, and Codex, with GPT-3 being the most notable. However, most of these models were proprietary and unavailable to the public. This has changed with recent releases like Dall-E for image generation and GitHub Copilot. Around this time it became clear that scaling language models up became less effective and too expensive for most companies. This was confirmed by Deepmind in 2022 in their research paper “Training Compute-Optimal Large Language Models” which showed that most LLMs are vastly undertrained and too big for their training data set.
OpenAI and others started to use other means to improve their models, such as reinforced learning. That led to InstructGPT which was fine-tuned to perform the described tasks. They used the same technique to fine-tune their model on dialog data which led to the famous ChatGPT.
How they work
The core of most modern machine learning architectures are neural networks. As the name suggests, they are inspired by their biological counterpart.
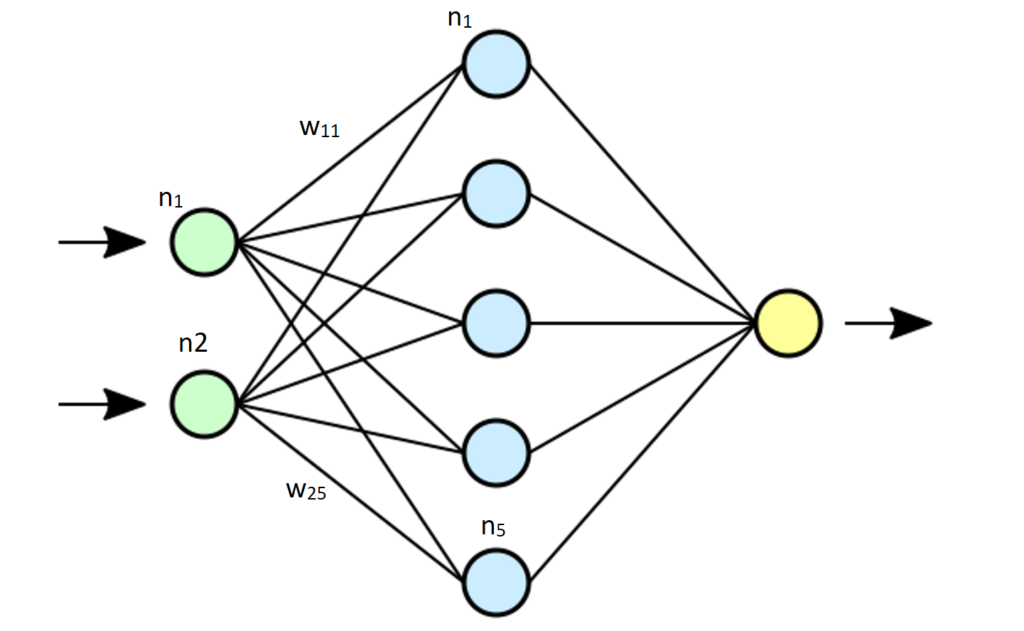
At a high level, a neural network consists of three main components: an input layer, one or more hidden layers, and an output layer. The input layer receives data, which is then processed through the hidden layers. Finally, the output layer produces a prediction or classification based on the input data.
The basic building block of a neural network is a neuron, which takes inputs, applies a mathematical function (activation function) to them, and produces an output. The output of each neuron ni is multiplied by the weight wij and added together into the neuron nj in the next layer until the output layer is reached. This process can be implemented as a simple matrix-vector multiplication with the input as the vector I and the weights as the matrix W: WxI = O, where O is the output vector which is used as the input for the next layer where we apply the activation function f(O) = I until the final output.
During training, the network is presented with a set of labeled examples, known as the training set. The network uses these examples to learn patterns in the data and adjust its internal weights to improve its predictions. The process of adjusting the weights is known as backpropagation.
Backpropagation works by calculating the error between the network’s output and the correct output for each example in the training set. The error is then propagated backwards through the network, adjusting the weights of each neuron in the opposite direction of the error gradient. This process is repeated for many iterations until the network’s predictions are accurate enough.
Since 2017 most LLMs are based on Transformers. Which also contain simple feed-forward networks, but at their core have a self-attention mechanism that allows the Transformer to detect dependencies between different words in the input.
The self-attention mechanism in the Transformer model works by using three vectors for each element of the input sequence: the query vector, the key vector, and the value vector. These vectors are used to compute an attention score for every element in the sequence. We get the score of the jth element by calculating the dot product of the query vector with every key vector ki of every element and multiplying the result with the value vector vi. We then sum up all the results to get the output.
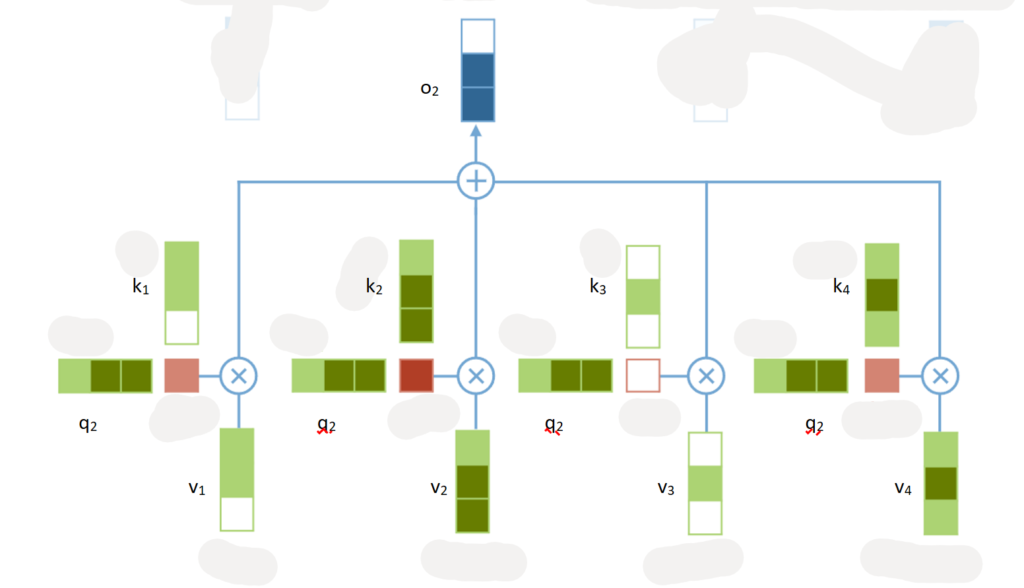
Before you multiply the attention score with the value vectors, you would first apply a softmax function to the attention scores. This will ensure that they add up to one and that the resulting weighted value vectors are weighted proportionally to their relevance to the query element. This weighted sum is then used as input to the next layer of the Transformer model. I skipped or simplified other parts of the algorithm as well to make it easier to understand. For a more in-depth explanation of Transformers, I recommend this blog or the creator of GPT himself.
The self-attention mechanism in the Transformer model allows the model to capture long-range dependencies and relationships between distant elements in the input sequence. By selectively attending to different parts of the sequence at each processing step, the model is able to focus on the most relevant information for the task at hand. This makes the Transformer architecture highly effective for natural language processing tasks, where capturing long-range dependencies is crucial for generating coherent and meaningful output.
What they can and cannot do
As explained earlier LLMs are text prediction systems. They are not able to “think”, “feel”, or “experience” anything, but are able to learn complex ideas to be able to predict text accurately. For example the sequence “2 + 2 =” can only be continued if there is an internal representation of basic math inside the Transformer. This is also the reason why LLMs often produce plausible-looking output that makes sense but is wrong. Since the model is multiple magnitudes smaller than the training data and even smaller compared to all possible inputs it is not possible to represent all the needed data. This means that LLMs are great for producing high-quality text about a simple topic, but they are not great at understanding complex problems that require a huge amount of available information and reasoning like mathematical proofs. This can be improved by providing needed information in the input sequence which will increase the probability of correct outputs. A great example would be BingGPT which uses search queries to get additional information about the input. You can also train LLMs to do this themselves by fine-tuning them on API calls.
What will they be able to do and what are the limits
The chinchilla scaling law shows that LLMs are able to adapt to even larger amounts of training data. If we can collect the needed amount of high-quality text data and processing power LLMs will be able to learn even more complex language-related tasks and will become more capable and reliable. They will never be flawless on their own and have the core problem that you are never able to understand how the output was produced as neural networks are black boxes for an observer. They will however become more general as they learn to use pictures, audio, and other sensory data as input, at which point they are barely still language models. The Transformer architecture however will always be a token prediction tool and will never develop “consciousness” or any kind of internal thought as they are still just several Matrix calculations on a fixed input. I suspect that we need at least some internal activity, and the ability to learn during deployment for AGI. But even without that, they will become part of most professions, hidden inside other applications like Discord, Slack, or Powerpoint.
Bias and other problems
LLMs are trained on large text corpora which are filled with certain views, opinions, and mistakes. The resulting output is therefore flawed. The current solution includes blocking certain words from input and/or output. Fine-tune with human feedback, or provide detailed instructions and restrictions in every prompt. They are all not flawless as blocking words is not precise enough. Added instructions can be circumvented by simply overwriting them with prompt injections. Fine-Tuning with human feedback is the best solution that comes with its own problem which is that the people who rate the outputs include their own bias in the fine-tuned model. This becomes a huge problem if you start using these models in education, communication, and other use cases. The views of the group of people who are controlling the training process are now projected onto everybody in the most subtle and efficient way imaginable. As OpenAI stated in their recent post the obvious solution will be to fine-tune your own model, which will lead to less outside influence but also increases the risk of shutting out other views and could create digital echo chambers where people put their radical beliefs into models and are getting positive feedback.
Another problem is that most people are not aware of how these systems work and terms like “artificial intelligence” suggest some form of being inside the machine. They start to anthropomorphize them and accept the AI unconsciously as another person. This is because our brains are trained to look at language as something only an intelligent being can produce. This starts by adding things like “thanks” to your prompt and then moves quickly to romantic feelings or some other kind of emotional connection. This will become increasingly problematic the better and more fine-tuned the models become. Adding text-to-speech and natural language understanding will also amplify this feeling.
Scaling
I see many people asking for an open-source version of chatGPT and wishing to have such a system on their computers. Compared to generative models like stable diffusion, LLMs are way bigger and more expensive to run. This means that they are not viable for consumer hardware. It takes millions of dollars in computing power to train and is only able to run on large servers. However, there are signs that this could change in the future. The Chinchilla scaling law implies that we can move a larger part of the computation into the training process by using smaller models with more data. An early example would be the new LLaMA models by Meta which are able to run on consumer hardware and are comparable to the original GPT-3. This still requires millions in training, but this can be crowdfunded or distributed. While these language models will never be able to compete with the state-of-the-art models made by large companies, they will become viable in the next 1-2 years and will lead to personalized fine-tuned models that take on the role of an assistant. Two excellent examples of open-source projects that try to build such models are “Open-Assistant” and “RWKV“.
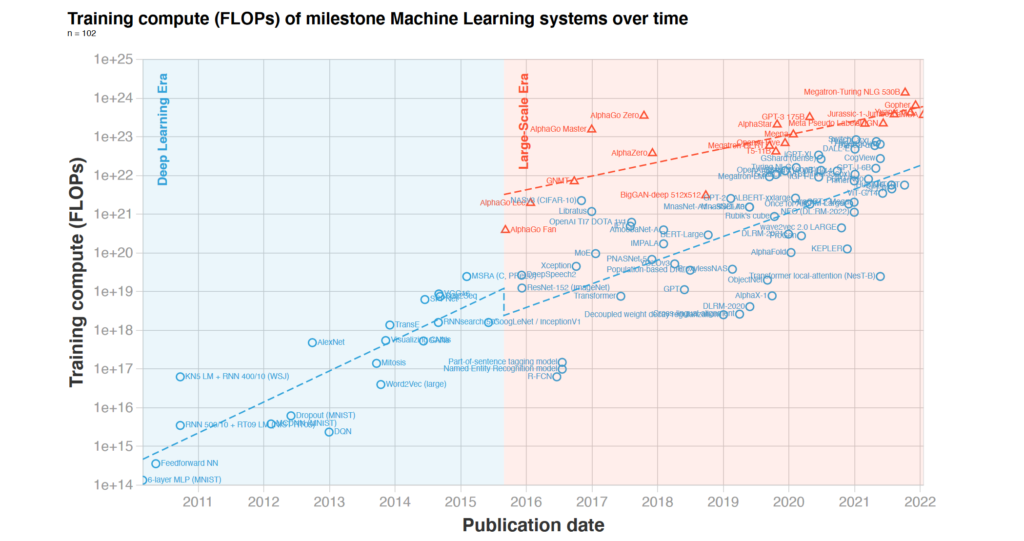
The current growth in computing will not be sustainable much longer as it is not only driven by Moore’s law, but also by an increase in investments in training which will soon hit a point where the return does not justify the costs. at this point, we will have to wait for the Hardware to catch up again.
What are the main use cases?
When ChatGPT came out, many used it like Google to get answers to their questions. This is actually one of the weak points of LLMs since they can only know what was inside their training data. They tend to get facts wrong and produce believable misinformation. This can be fixed by including search results like Bing is doing.
The better use case is creative writing and other text-based tasks like summarising, explaining, or translating. The biggest change will therefore happen in jobs like customer support, journalism, and teaching. The education system in particular can benefit greatly from this. In many countries, Germany for example, teachers are in need. Classes are getting bigger and lessons are less effective. Tools like ChatGPT are already helping many students and when more specialized programs use LLMs to provide a better experience they will outperform traditional schools soon. Sadly many schools try to ban ChatGPT instead of including it which is not only counterproductive but is also not possible since there are no tools that can accurately detect AI-written text. But text-based tasks are not the limit. Recent papers like Toolformer show that LLMs will soon be able to control and use other hard and software. This will lead to numerous new abilities and will enable them to take over a variety of new tasks. A personal assistant as Apple promised us years ago when they released Siri will soon be a reality.
Leave a Reply